MinHash is a simple algorithm allowing to compute probabilistically the similarity of two set A and B according to the Jaccard similarity coefficient.
The two extreme values are 0 (no value in common) and 1 (the two set contains the same elements).
In the classical case, if you want to know which is the similarity between two sets of n and m elements, in the worst case, where you compare each element to each others, you need to do n * m comparisons. You can improve this number by sorting elements, and other tricks.
If elements are not "simple" as float, characters or boolean values, like strings or multidimentional objects, the number of comparison can be very high.
CostK be the cost to compare two elements.
Two choices for exact calculation:
Compare all non sorted elements together CostK(n * m)
Sort the two sets and compare each ordered set together CostK(nlogn + mlogm + max(n, m)) ≤ CostKmax(n, m)(1 + log(max(n, m)))
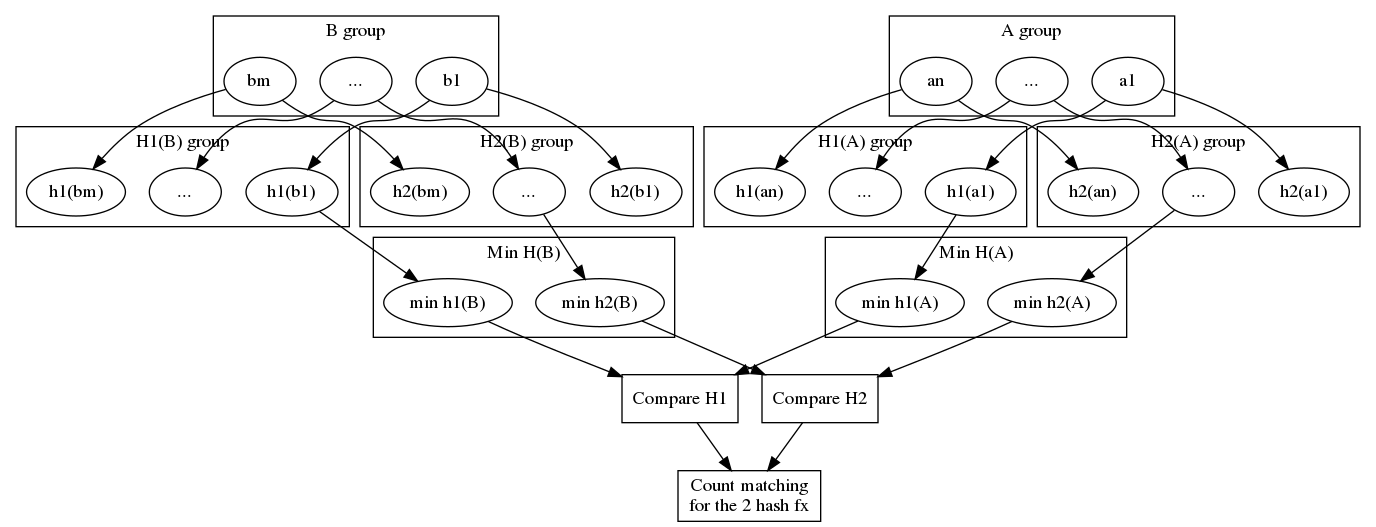
Be K the object space, A and B two set of n and m elements respectively with value in K. Be H the set of j hashing functions, with jinf min(n, m).
A = {ai ∈ K|i ∈ [1, n]}
B = {bi ∈ K|i ∈ [1, m]}
H = {hi|i ∈ [1, j]}, H : K ↦ R
For all elements of A and B, we compute all the H hash function over all elements, and keep for each set the minimal values founds. This require n * j and m * j operation for each set, plus sorting the value, that can be done in j * nlog(n) and j * mlog(m).
After keeping the smallest values for each hashing function of both set, all j pair of values are compared, leading to j comparison only.
The Jaccard coefficient can be approximed as
Defining Cost(h) the cost for computing the hash function over an object of K, and Cost(cmp) the cost for comparing two hash values, under the hypothesis that all hash values have the same comparison cost, the number of operation can be summarized as :
j * Cost(h)*(n + m)+j * Cost(cmp)*(nlog(n)+mlog(m)+1)≤2 * p * j * (Costh + Costcmp * log(p)) + j * Costcmp with p = min(m, n)
Example with two set A and B with 2 hash functions.
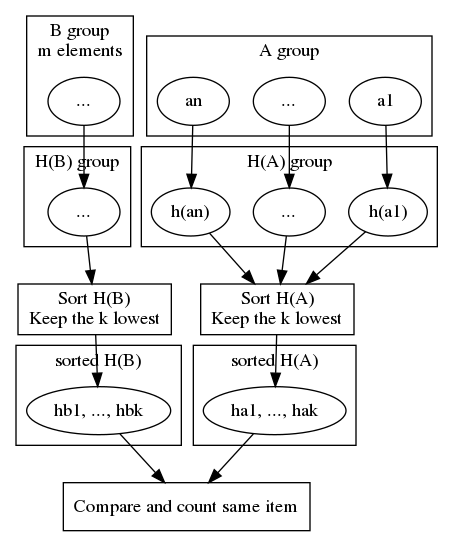
Instead of using multiple hash functions, we use only one, and rank hashed values.
Be h : K ↦ R
Calculate H(A)={h(a)|∀a ∈ A} Sort H(A) and keep the k lowest values H(A)k = {h(ai)|i ∈ [1, k − 1],h(ai)≤h(ai + 1)} Do the same for B and compare elements of each hash value sets together.
For this variant, it cannot be calculated with k comparisons, as values are all in the same space. The comparison has to be made using exact techniques, with 2k comparisons, which is still very good (as values are already sorted).
Costh(n + m)+Costcmp(nlogn + mlogm + 2k)